Git 的诞生
很多人都知道,Linus 在 1991 年创建了开源的 Linux,从此,Linux 系统不断发展,已经成为最大的服务器系统软件了。Linus 虽然创建了 Linux,但 Linux 的壮大是靠全世界热心的志愿者参与的,这么多人在世界各地为 Linux 编写代码,那 Linux 的代码是如何管理的呢?
在 2002 年以前,世界各地的志愿者把源代码文件通过 diff 的方式发给 Linus,然后由 Linus 本人通过手工方式合并代码!你也许会想,为什么 Linus 不把 Linux 代码放到版本控制系统里呢?不是有 CVS、SVN 这些免费的版本控制系统吗?因为 Linus 坚定地反对 CVS 和 SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比 CVS、SVN 好用,但那是付费的,和 Linux 的开源精神不符。
到了 2002 年,Linux 系统已经发展了十年了,由于代码库变得巨大,让 Linus 很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是 Linus 选择了一个商业的版本控制系统 BitKeeper,BitKeeper 的东家 BitMover 公司出于人道主义精神,授权 Linux 社区免费使用这个版本控制系统。
但是安定团结的大好局面在 2005 年就被打破了,原因是 Linux 社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发 Samba 的 Andrew 试图破解 BitKeeper 的协议(这么干的其实也不只他一个),被 BitMover 公司发现了(监控工作做得不错!),于是 BitMover 公司怒了,要收回 Linux 社区的免费使用权。
Linus 可以向 BitMover 公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是这样的:Linus 花了两周时间自己用 C 写了一个分布式版本控制系统,这就是 Git!一个月之内,Linux 系统的源码已经由 Git 管理了!牛是怎么定义的呢?大家可以体会一下。
Git 迅速成为最流行的分布式版本控制系统,尤其是 2008 年,GitHub 网站上线了,它为开源项目免费提供 Git 存储,无数开源项目开始迁移至 GitHub,包括 jQuery,PHP,Ruby 等等。
历史就是这么偶然,如果不是当年 BitMover 公司威胁 Linux 社区,可能现在我们就没有免费而超级好用的 Git 了。
集中式与分布式
前面提到,CVS 及 SVN 都是集中式的版本控制系统,而 Git 是分布式版本控制系统,那么这两者有什么区别呢?
集中式
集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了再放回图书馆。
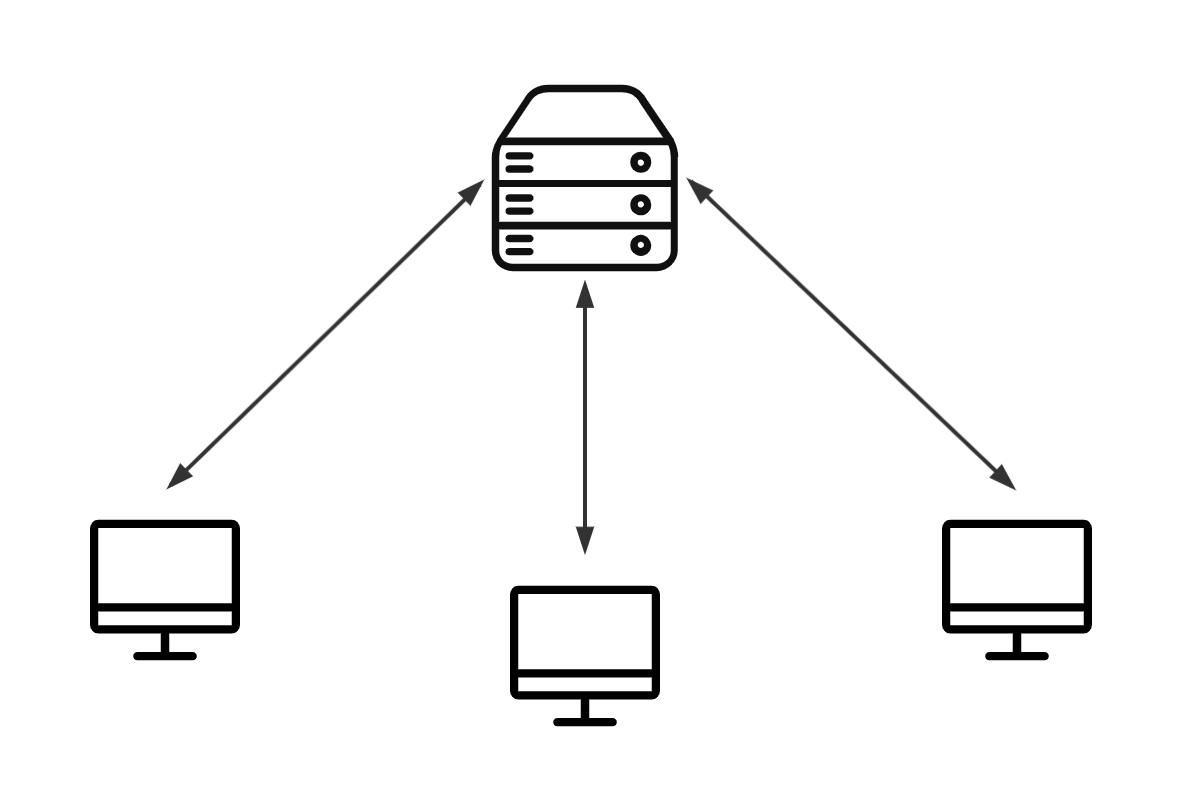
集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个 10M 的文件就需要 5 分钟,这还不得把人给憋死啊。而且在平时的开发中,由于每个开发者的修改,经常是反复持续进行,在修改的过程中,总会遇到未能稳定、完备到足以提供其他开发者使用的程度,若是在此时提交到仓库,便有可能让仓库的代码处于不稳定、不成熟的状态。当然,也可以让开发者持续修改至足够稳定完备后,再将修改内容提交至仓库。但是,在这个空窗期里,开发者就无法享受到版本控制的好处,他没有办法将修改过程中的不同阶段,划分成为多个版本。关键的是,如果集中式版本控制系统的中央服务器出了问题,那么所有人都没办法干活了。
分布式
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库。版本库中包含了完整的版本管理数据、例如提交信息、版本变化记录等等。因此,所有对版本控制系统的操作,都可以直接在本机端的版本库中进行,包括提交、分支、合并、回退等。这样做的好处是,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。而每个开发者都拥有独立的版本库,所以可以直接对自己的版本库进行操作。在离线环境中,开发者既可以连续工作,也可以持续修改,和本地版本库进行交互(比如管理版本、查询修改历史、回溯、提交、……)。这样使得开发者不需要将自己的修改持续送至集中的档案库上,造成其他开发者必须套用这些修改,引起可能的不稳定情况。
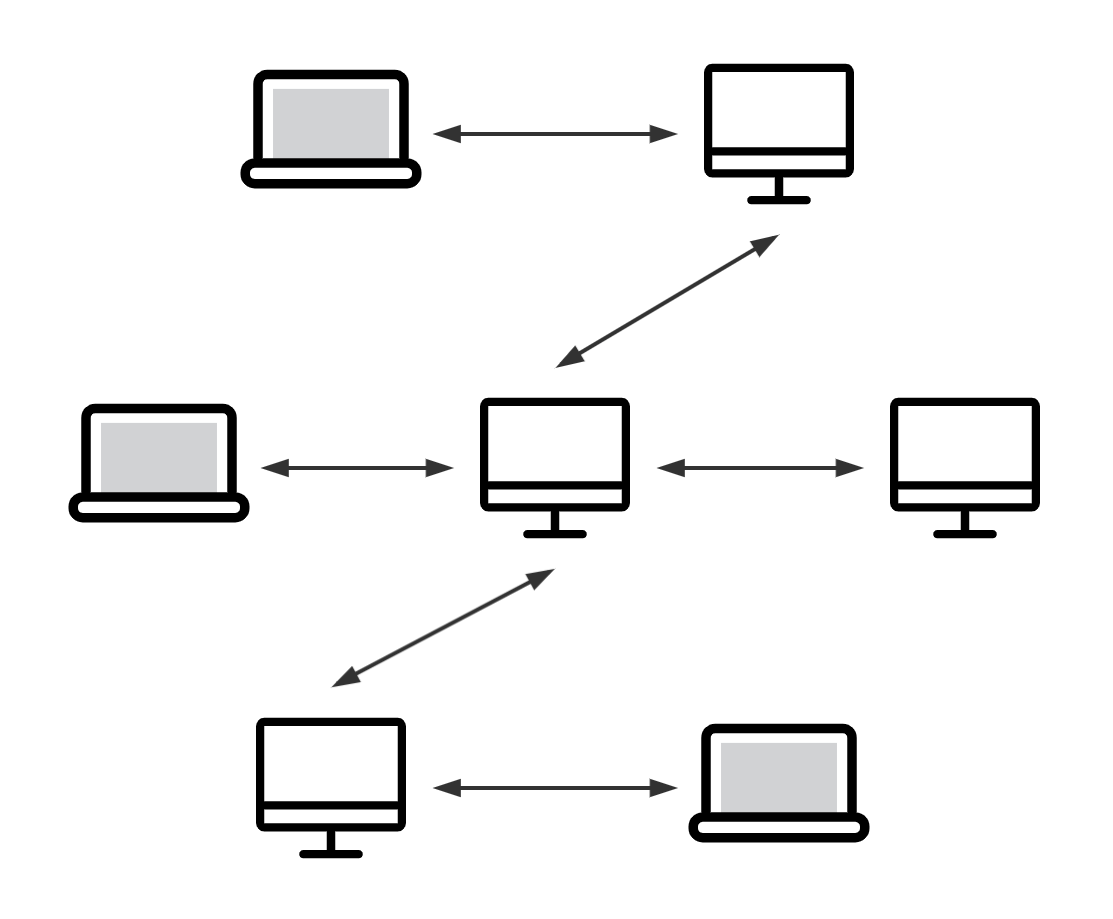
当然,Git 的优势不单是不必联网这么简单,后面我们还会看到 Git 极其强大的分支管理,把 SVN 等远远抛在了后面。
Git 术语
我们在使用 Git 时,会遇到许多术语,这里先进行总结,方便后面学习中的理解。
工作区(Workspace)
就是你在电脑里能看到并且进行工作的目录
暂存区(stage/index)
在平时开发时,当进行 commit 操作后(提交到本地仓库,后面会讲),会为这个操作生成日志并保存版本,但是我们有时只想单纯的保存一下代码,并不想直接作为一个版本保存,这就需要暂存区为我们“暂时存一下”。暂存区在 ".git 文件" 目录下的 index 文件(.git/index)中,所以我们把暂存区有时也叫作索引(index)。
本地仓库(Repository)
可以简单理解成一个目录,这个目录里面的所有文件都可以被 Git 管理起来,每个文件的修改、删除,Git 都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。正是因为本地仓库的存在,才使 Git 可以在离线的情况下做管理版本、查询修改历史、回溯、提交等操作。
远程仓库(Remotes)
Git 并不像 SVN 那样有个中心服务器,所以远程仓库中的词语“远程”,未必表示仓库在网络或互联网上的其它位置,而只是表示它在别处。 我们在本地仓库、暂存区、工作区所进行的代码版本维护操作都是在本地执行的,而如果你想通过 Git 分享你的代码或者与其他开发人员合作, 你就需要将数据放到一台其他开发人员能够连接的服务器上。简单的说,没有远程仓库不会影响我们对代码版本的维护,但如果想分享代码,必须要有个远程仓库。常见的远程仓库有 github、gitee(码云)、gitlab 等。gitlab 是可以在企业内部搭建,可以创建私有的代码仓库,所以一般企业会部署 gitlab 存放私有代码。
分支(Branches)
一个分支意味着一个独立的、拥有自己历史信息的代码线(code line)。你可以从已有的代码中生成一个新的分支,这个分支与剩余的分支完全独立。使用分支意味着你可以从开发主线上分离开来,然后在不影响主线的同时继续工作。有人把 Git 的分支模型称为必杀技特性,而正是因为它,Git 从版本控制系统家族里脱颖而出。
标签(Tags)
标签可以记录某个分支某个特定时间点的状态。如果我们的代码达到一个重要的阶段,可以为其打上标签,通过标签可以很方便的切换到标记时的状态,例如 2009 年 1 月 25 号在 testing 分支上的代码状态。
Git 工作原理
分支原理
不只是 Git 有分支,几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离开来,以免影响开发主线。 在很多版本控制系统中,这是一个略微低效的过程——常常需要完全创建一个源代码目录的副本。对于大项目来说,这样的过程会耗费很多时间。而 Git 处理分支的方式可谓是难以置信的轻量,创建新分支这一操作几乎能在瞬间完成,并且在不同分支之间的切换操作也是一样便捷。 与许多其它版本控制系统不同,Git 鼓励在工作流程中频繁地使用分支与合并,哪怕一天之内进行许多次。 理解和精通这一特性,你便会意识到 Git 是如此的强大而又独特,并且从此真正改变你的开发方式。
在分支方面,Git 保存的不是文件的变化或者差异,而是一系列不同时刻的快照 。在进行提交操作时,Git 会保存一个提交对象(commit object)。 知道了 Git 保存数据的方式,我们可以很自然的想到——该提交对象会包含一个指向暂存内容快照的指针。 但不仅仅是这样,该提交对象还包含了作者的姓名和邮箱、提交时输入的信息以及指向它的父对象的指针。 首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象, 而由多个分支合并产生的提交对象有多个父对象,为了更加形象地说明,我们假设现在有一个工作目录,里面包含了三个将要被暂存和提交的文件。 暂存操作会为每一个文件计算校验和 SHA-1 哈希算法,然后会把当前版本的文件快照保存到 Git 仓库中(Git 使用 *blob *对象来保存它们),最终将校验和加入到暂存区域等待提交:
git add README test.rb LICENSE
git commit -m 'The initial commit of my project'git add README test.rb LICENSE
git commit -m 'The initial commit of my project'当使用 git commit 进行提交操作时,Git 会先计算每一个子目录的校验和, 然后在 Git 仓库中这些校验和保存为树对象。随后,Git 便会创建一个提交对象, 它除了包含上面提到的那些信息外,还包含指向这个树对象(项目根目录)的指针。 如此一来,Git 就可以在需要的时候重现此次保存的快照。
由于 Git 的分支实质上仅是包含所指对象校验和长度为 40 的 SHA-1 值字符串的文件,所以它的创建和销毁都异常高效。 创建一个新分支就相当于往一个文件中写入 41 个字节(40 个字符和 1 个换行符),如此的简单能不快嘛。这与过去大多数版本控制系统形成了鲜明的对比,它们在创建分支时,将所有的项目文件都复制一遍,并保存到一个特定的目录。 完成这样繁琐的过程通常需要好几秒钟,有时甚至需要好几分钟。所需时间的长短,完全取决于项目的规模。 而在 Git 中,任何规模的项目都能在瞬间创建新分支。 同时,由于每次提交都会记录父对象,所以寻找恰当的合并基础(即共同祖先)也是同样的简单和高效。 这些高效的特性使得 Git 鼓励开发人员频繁地创建和使用分支。后面我们会讲到分支运用时的实际流程。
Git 的使用
diff 及工作区撤销
本地编写的代码,不执行任何 Git 命令,处于工作区,此时我们可以通过 git diff 查看工作区的修改。如果我们不想要某个文件的修改,可以使用 git checkout -- [file] 撤销文件修改,命令中 [file] 为所要撤销的具体文件路径。如果想要撤销所有本地修改,可以使用 git checkout -- . 来操作。但是要注意的是,通过此处撤销命令所撤销的修改,不可二次撤销,一旦执行将无法通过 Git 找回撤销内容。撤销之后再次执行 git diff 命令将没有任何输出,表示工作区没有修改内容。
add 及暂存区撤销
当工作区的代码完成之后,我们需要先执行 git add . 将工作区内的所有修改添加到暂存区,也可以使用 git add [file] 添加某个文件的修改到暂存区,命令中 [file] 为所要添加的具体文件路径。执行添加所有修改操作之后,我们执行 git diff 命令将不会有任何输出(因为此时修改已添加到暂存区),想要查看暂存区的修改,可以使用 git diff --staged 来查看,其输出与 git diff 的输出形式一模一样。这个时候我们想要撤销暂存区的全部修改,可以使用 git reset . 来操作,也可以使用 git reset [file] 撤销某个文件,命令中 [file] 为所要撤销的具体文件路径。此撤销命令是可二次撤销的,因为撤销后修改会回到工作区,通过 git add 命令可以将修改再一次添加到暂存区。暂存区与工作区的撤销操作可以使用 git reset --hard 合并成一次操作(不推荐使用)。
commit 及本地仓库撤销
当我们的代码开发到一定的阶段后,可以使用 git commit -m "log" 将暂存区的代码提交到本地仓库并生成快照(便于回退等操作),命令中 "log" 处可以让我们为此次提交写一些日志,方便记忆及与他人协作, commit 操作可以将多次的暂存合并提交。当代码提交后,我们可以使用 git log 查看提交历史,在不传入任何参数的默认情况下,git log 会按时间先后顺序列出所有的提交,最近的更新排在最上面,也可以使用 git log -2 过滤出最新的两条提交。每一条提交历史会列出当时提交的 SHA-1 校验(commit 后面的很长的编码)、作者的名字、作者的电子邮件、提交时间以及提交说明。如果我们不想要最新修改的内容,有两种方法进行撤销操作。第一种方法(不推荐,仅供了解)是使用 git checkout [SHA-1] 进行操作,这个方法可以让我们切换到任意提交时刻,命令中 [SHA-1] 指的是提交历史中 commit 后面很长的编码,在这里可以使用全称,也可以简写成前面 7 个编码。第二种方法是使用 git reset --hard HEAD^ 进行操作。在 Git 中,用 HEAD 表示当前版本, HEAD^ 代表上个版本,上上个版本可以表示为 HEAD^^ ,但是我如果向上 100 个版本,我们总不能写 100 个 ^ 吧,所以我们可以用 HEAD~100 来表示,那么上个版本也可以写成 HEAD~1 。此撤销命令是可二次撤销的,当第一次撤销后我们使用 git log 会发现撤销前的提交已经不见了,所以我们可以使用 git reflog 查看使用过的每一次命令,在这里我们可以找到撤销前那次提交的 SHA-1,使用 git reset --hard [SHA-1] 即可二次撤销。
分支及其操作
不知你是否还记得在二次撤销时我建议使用 HEAD 方法,这是因为 Git 的原理最精华的部分就是指针,而 HEAD 便是 Git 的指针。Git 的默认分支是 master ,它与其他分支并没有什么不同,只是开发时我们一般会把它看做“根分支”。我们使用 git branch [name] 来新建分支,命令中 [name] 指的是你为新分支起的名字。当你新建分支时,Git 为你创建了一个可以移动的新的指针,而指针指向当前位置,HEAD 并不会自动切换到新分支中去。我们可以使用 git log --decorate 来查看各个分支当前所指的对象,HEAD 所指向的分支就是我们当前所在的分支。需要注意的是,HEAD 和分支都是指针,HEAD 指向代表分支的指针,表示我们在那个所指的分支。如果想看当前所指的分支以及有哪些分支,可以使用 git branch 查看。
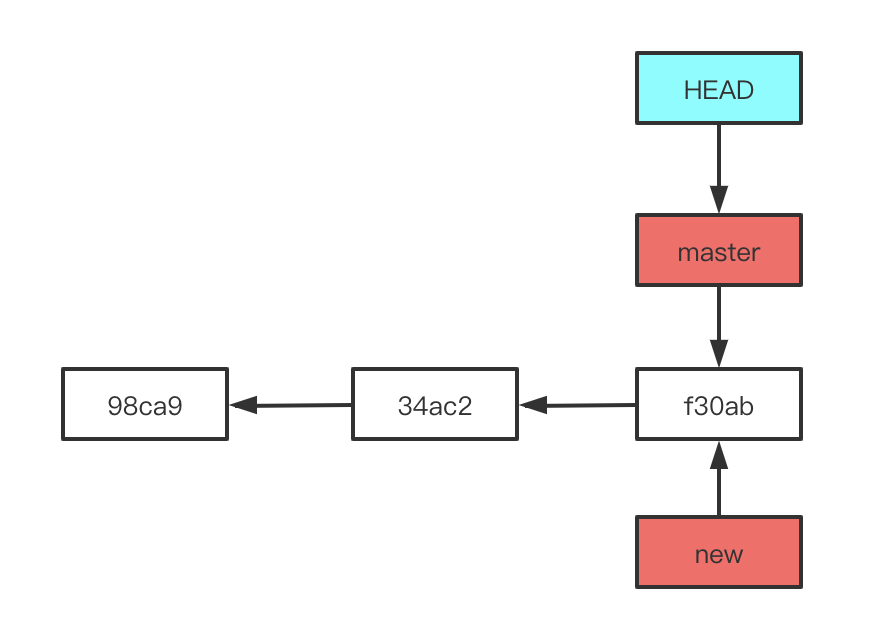
当我们新建分支后,可以使用 git checkout [branchName] 切换分支,命令中 [branchName] 指的是所要前往的分支名,操作过后 HEAD 会指向切换的分支。我们也可以使用 git checkout -b [branchName] 命令在新建一个分支的同时切换过去,简化新建分支和切换分支的操作。
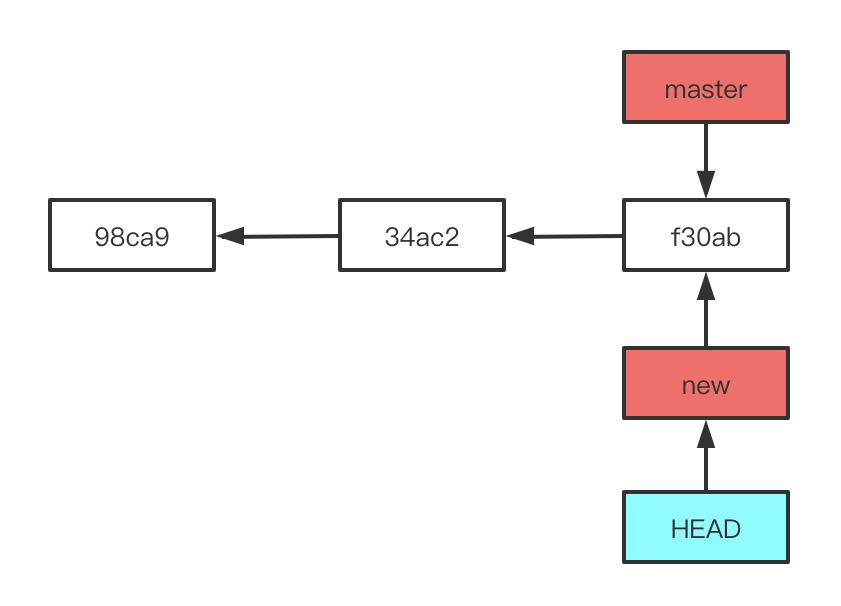
当我们新建并切换分支后,对代码进行修改并提交(commit),你会发现 HEAD 与其所指的分支(也就是你当前所在分支)随着提交操作自动向前移动,而 master 分支并没有移动,它仍然指向运行 git checkout 时所指的对象。此时我们切换回 master 分支后,会发现我们对代码的修改消失了,切换回之前的分支修改就又回来了。也就是说,此时我们切换回 master 分支后,HEAD 会指回 master 分支,工作目录恢复成 master 分支所指向的快照内容。
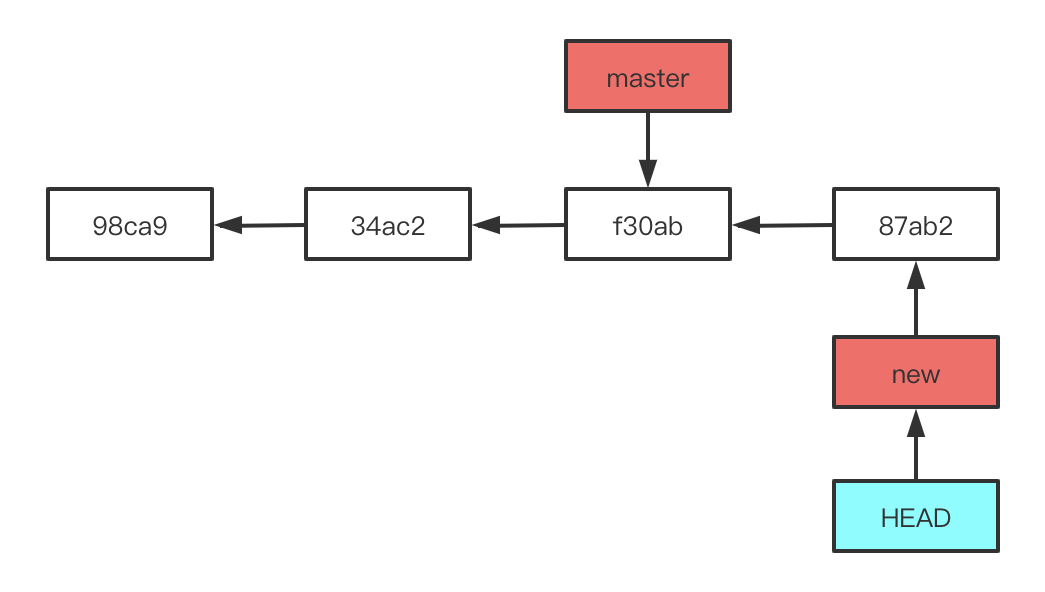
当我们切换到 master 分支并进行代码修改的话,修改内容是基于 master 所在快照的,本质上来讲,这就是忽略之前新建分支所做的修改,向另一个方向进行开发。此时我们将在 master 分支所修改的代码提交,那么这个项目的提交历史会产生分叉。
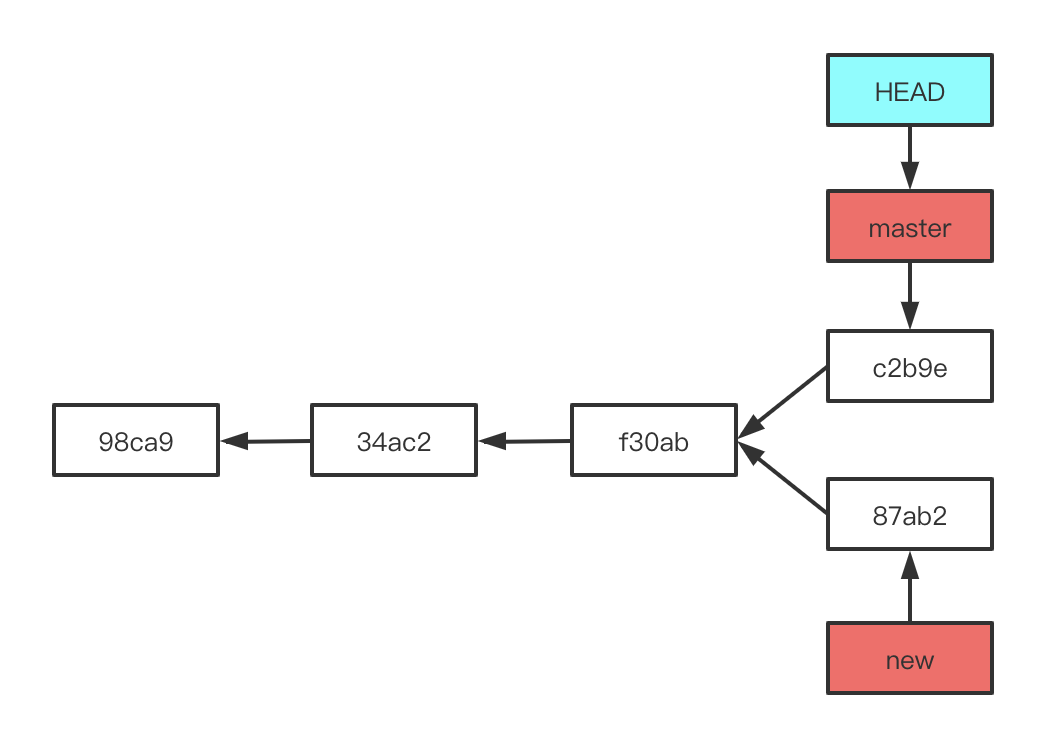
现在我们的事例中有两条分支,而我不愿意放弃任何分支,并且他们对我的项目都有用怎么办呢?这时我们需要合并分支操作。Git 的分支操作可以使用 git merge 和 git rebase ,这里我们先简单的讲解一下 merge 的使用,其他操作命令以及命令的区别我会出一个专题讲解。merge 是一个将其他分支合并到当前所在分支的命令,所以在使用命令时先确保自己所在分支没问题,然后使用 git merge [branchName] 命令,命令中 [branchName] 指的是被合并的分支,此命令会留下两个分支的操作历史。
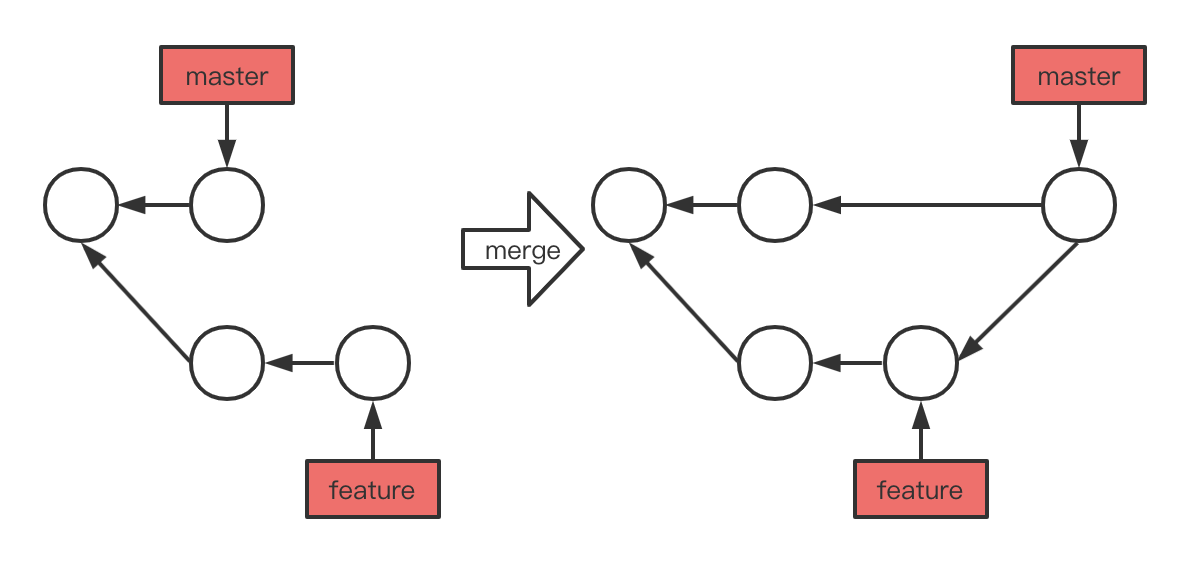
我们可以看到,当进行操作时 Git 做了一个新的快照并且自动创建一个新的提交指向它。这个被称作一次合并提交,它的特别之处在于他有不止一个父提交。而这整个分支变动会被记录在代码历史中。合并完分支后,如果被合并的分支没有用处了,我们可以使用 git branch -d [branchName] 删除分支。有时候合并操作不会如此顺利, 如果你在两个不同的分支中,对同一个文件的同一个部分进行了不同的修改,Git 就没法干净的合并它们。当出现合并冲突时,Git 不会自动地创建一个新的合并提交,它会暂停下来等待我们去解决合并产生的冲突。任何因包含合并冲突而有待解决的文件,都会以未合并状态标识出来。 Git 会在有冲突的文件中加入标准的冲突解决标记,这样你可以打开这些包含冲突的文件然后手动解决冲突。 出现冲突的文件会包含一些特殊区段,看起来像下面这个样子:
<<<<<<< HEAD:index.html
<div id="footer">Old code</div>
=======
<div id="footer">New code</div>
>>>>>>> feature:index.html<<<<<<< HEAD:index.html
<div id="footer">Old code</div>
=======
<div id="footer">New code</div>
>>>>>>> feature:index.html这表示 HEAD 所指示的版本在这个区段的上半部分(======= 的上半部分),而 feature 分支所指示的版本在 ======= 的下半部分。 为了解决冲突,你必须选择使用由 ======= 分割的两部分中的一个,或者你也可以自行合并这些内容。当我们使用 Vscode、Webstorm 等 ide 工作时,解决冲突会变得更容易。当我们解决了所有文件里的冲突之后,使用 add 命令来将其标记为冲突已解决。 一旦暂存这些原本有冲突的文件,Git 就会将它们标记为冲突已解决。当我们检查完所有合并文件没问题后,可以使用 commit 命令来完成合并提交。最后,我们可以使用 git log --oneline --graph --all 来查看提交记录的分支图。
Git 的其他操作
如今程序员之间比较流行的远程代码仓库有 GitHub、Gitee 等,我比较推荐大家使用 Gitee 来储存代码,毕竟国内访问 Gitee 的速度很快。而有时我们需要使用其他仓库,而速度很慢怎么办呢?可以通过“魔法”,然后改变 Git 的 global 来适当的提升速度。使用 git config --global 命令可以设置,为了防止所有地址都被拦截,我们可以定向的设置,例如 git config --global http.https://github.com.proxy socks5://127.0.0.1:49166 则是定向的拦截 https://github.com.proxy 请求。当我们设置好后,可以通过 git config --global -l 查看我们设置的所有 global。
由于时间不足,先写到这里,今后会慢慢补充!

